One of the more popular standards for reversible image compression, is Compuserve's Graphics Interchange Format (GIF) described in [13] for the original 1987-version, and in [14] for the extended 1989-version. GIF compression is done using the Lempel-Ziv-Welch (LZW) algorithm, based on LZ78. Using the term ``reversible'' when describing GIF may, in some cases, be a misnomer, as images will have to be quantized to 256 colors before being coded. If the original image contains more than 256 colors, it will not be fully reproducible after coding with GIF. Due to the dictionary based coding, the compression performance of GIF is best when coding images containing repeated patterns, as is often the case with computer generated images and simple line drawings.
Most methods for irreversible, or ``lossy'' digital image compression, consist of three main steps: Transform, quantizing and coding, as illustrated in figure 2.1.

Figure 2.1: The three steps of digital
image compression.
The purpose of the transform is to reorganize the data, to make it possible for the encoder to do a better job. For statistical coders, the transform can typically be to give the data a representation featuring non-uniform probability distribution.
The quantizing step is used to remove or reject information that is regarded uninteresting. What is considered uninteresting, depends on how the image is supposed to be used later. If the image is targeted at a human observer, which is the case for the video images covered by this report, the quantizing will typically remove details which are not registered by our visual system.
The final step, coding, produces the resulting bitstream using an appropriate, general compression algorithm.
An irreversible method yields a result after decompression that, using an appropriate quality measure, is close to the original.
JPEG is an international standard for color image compression, created
from a cooperative effort between the three major standardization
organizations ISO![]() , CCITT
, CCITT![]() and
IEC
and
IEC![]() . The acronym JPEG is short for ``Joint Photographic
Experts Group''. The book [15], written by two members of
the standardization working group, is a comprehensive guide to the
inner workings of JPEG. It also features a copy of the JPEG draft
international standard as an appendix. A shorter introduction to JPEG
is given in a ``classical'' article [16] by Gregory K.\
Wallace, once chairman of JPEG. A comparison between GIF and JPEG may
be found in [17].
. The acronym JPEG is short for ``Joint Photographic
Experts Group''. The book [15], written by two members of
the standardization working group, is a comprehensive guide to the
inner workings of JPEG. It also features a copy of the JPEG draft
international standard as an appendix. A shorter introduction to JPEG
is given in a ``classical'' article [16] by Gregory K.\
Wallace, once chairman of JPEG. A comparison between GIF and JPEG may
be found in [17].
JPEG offers many modes of operation with variations in pixel depth, number of color components, color component interleaving, pixel order, and coding algorithm. It even offers a reversible mode. We focus on the way images are treated to make high levels of irreversible compression possible. What is described here, is also relevant for the video sequence compression described in later sections.
The heart of irreversible JPEG, is a 2D version of a mathematical transform known as Discrete Cosine Transform (DCT). The goal of the transform is to decorrelate the original signal, distributing the signal energy to only a small set of coefficients [12]. After the transform, many coefficients may be discarded without, or with little, loss of visual quality.
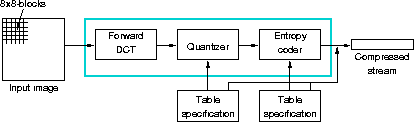
Figure 2.2: Pipeline for DCT-based coding (from the ISO
JPEG draft standard [15, Appendix A,]).
Figure 2.2 shows the main steps in converting a band
(a color component) of an image to a compressed bitstream using
DCT-based schemes, such as JPEG. An image is subdivided in
blocks of 8 ![]() 8 pixels, each of which are handled independently.
8 pixels, each of which are handled independently.
In the JPEG standard, the forward transform (FDCT) and the corresponding inverse transform (IDCT) to be performed on each block (matrix), are defined as
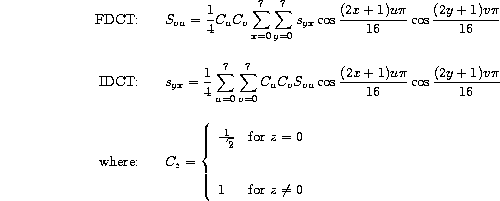
When using FDCT, blocks are transformed, to 8 ![]() 8 matrixes of
transform coefficients. Figure 2.3 illustrates
the naming conventions for transform coefficients.
8 matrixes of
transform coefficients. Figure 2.3 illustrates
the naming conventions for transform coefficients.
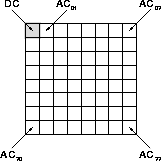
Figure 2.3: DC- and AC-coefficients.
The DC coefficient is proportional to the average pixel value in the
original block. AC-coefficients close to DC represent highly
correlated pixel values (low frequency), while AC-coefficients towards
the lower right corner represent rapidly changing pixel values (high
frequency), such as edges and noise. Using FDCT, most of the energy
is collected in the coefficients near DC, with decreasing energy
levels towards the lower right AC ![]() -coefficient, i.e. the upper
left coefficients are more important to visual quality when restoring
the image.
-coefficient, i.e. the upper
left coefficients are more important to visual quality when restoring
the image.
Quantization is done by dividing and truncating each of the
transformed coefficients by individual values. The values are given in
a quantization matrix, which becomes a part of the compressed
stream![]() (the leftmost
``table specification'' in figure 2.2). Quantization
is the greatest source to loss of information, as decimal digits are
discarded in the truncation. The quantization matrix typically
contains higher values towards the lower right, giving several of the
less important coefficients a zero value.
(the leftmost
``table specification'' in figure 2.2). Quantization
is the greatest source to loss of information, as decimal digits are
discarded in the truncation. The quantization matrix typically
contains higher values towards the lower right, giving several of the
less important coefficients a zero value.
Before coding, the quantized block is converted to a sequence of numbers by collecting coefficients according to the zig-zag sequence in figure 2.4.
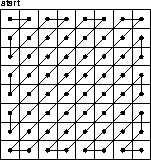
Figure 2.4: The zig-zag sequence.
The zig-zag sequence orders the coefficients in approximately decreasing importance, collecting the more heavily quantized values towards the end. This ordering typically gives runs of zero values, which are runlength encoded. Non-zero values are coded using either Huffman or arithmetic coding. A Huffman code table or an arithmetic coding decision table is sent as part of the compressed stream (the rightmost ``table specification'' in figure 2.2).
Decompressing a JPEG stream to an image resembling the original, is done using the pipeline in figure 2.5. The process is the reverse of coding.
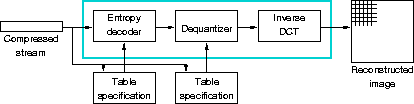
Figure 2.5: Pipeline for DCT-based decoding (from the ISO
JPEG draft standard [15, Appendix A,]).
Tables for the Huffman or arithmetic decoder is read from the stream,
along with quantization matrixes for the dequantizer. After decoding,
the dequantizer multiplies the DCT coefficients with the values found
in the quantization matrix, before sending the matrix to the inverse
DCT. Running IDCT results in an 8 ![]() 8 block, a part of the
reconstructed image.
8 block, a part of the
reconstructed image.
The JPEG standard doesn't specify how color images are supposed to be split in components. An advisory part of the standard does, however, specify sample quantization matrixes for intensity bands, and chrominance bands. As the human visual system is more sensitive to intensity changes than variations in colors, chrominance bands may be quantized more than intensity bands. JPEG File Interchange Format (JFIF) [18] specifies the use of the YCbCr color model for coded images.
JPEG has been used for video compression, by individually compressing each frame of the video stream. JPEG used for video sequences is often referred to as ``motion JPEG'' or ``M-JPEG'', but there is no agreed upon standard for this kind of compression. Different vendors have taken different approaches, with incompatible results [19].