The following sections are meant to give a quick introduction to basic compression algorithms. Algorithms for decompression are left out. For every algorithm, pointers to literature that further enlighten the topic are given.
A number of compression or coding algorithms assign codes of variable length to symbols, or groups of symbols depending on probability distribution. Examples of such algorithms include Huffman and Shannon-Fano coding. Implementations of these algorithms are called statistical coders. A non-uniform probability distribution is required for these coders to have any effect.
See [82] for complete explanation, and details of implementation of statistical coders. Also, the Frequently Asked Questions (FAQ) [83] from the comp.compression newsgroup may be helpful.
Statistical coders build code tables that are used for mapping between
symbols and codes. Coders are often categorized by how this table is
built![]() .
.
In Huffman coding, codes are generated with the aid of a binary tree according to the following algorithm:
We wish to code the text ``abracadabra''. To code this without
compression, we need three bits for each symbol, since the alphabet
contains 5 symbols![]() . The uncompressed text will thus occupy
. The uncompressed text will thus occupy
![]() bits.
bits.
Let's see how much we can hope to achieve by calculating the entropy of the text. To do this, we first calculate the information of each symbol, and sum this up in table A.1.
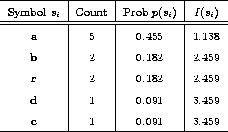
Table A.1: Statistics for the text
``abracadabra''
According to the formula, the entropy thus becomes 2.040. Following the algorithm above, we build the tree in figure A.1
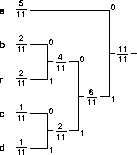
Figure A.1: An example Huffman tree for coding
``abracadabra''.
The algorithm states that one is to combine nodes containing the lowest probability. When several nodes with equal probability exists, one will have multiple choices. In figure A.1 the combinations is done as high in the tree as possible, to reduce the variance in the code length.
By traversing the tree, we end up with the codes in table A.2:
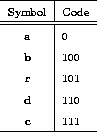
Table A.2: Huffman-codes for ``abracadabra''
The text is coded to the sequence 01001010111011001001010, containing 23 bits. On average, we have used 2.091 bits per symbol, quite close to the entropy. Compare this to the three bits used when coding directly without compression.
The drawback with Huffman coding, is that we assign an integer number
of bits as the code for each symbol. The code is thus optimal when
each symbol has an occurrence probability of ![]() [12].
[12].
Arithmetic coding takes another approach. Instead of assigning a code
for each symbol in the stream, the entire stream is given a single
code. The code is a number in the interval ![]() ,
possibly containing a large number of digits. The coding is done by,
for each symbol, shrinking the interval according to the following
algorithm
,
possibly containing a large number of digits. The coding is done by,
for each symbol, shrinking the interval according to the following
algorithm![]() :
:
Again, we wish to code the text ``abracadabra''. The initial interval must thus be divided in the subintervals given in table A.3:
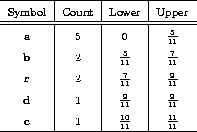
Table A.3: Subintervals for arithmetic coding of
``abracadabra''
When coding, the first symbol shrinks the current interval to
![]() . This interval is split in five new
subintervals, one for each symbol in the alphabet. Further coding
shrinks the interval more, finally giving us
. This interval is split in five new
subintervals, one for each symbol in the alphabet. Further coding
shrinks the interval more, finally giving us
![]() . The final code is
some number within this interval. Optimally, we choose the number that
can be coded with less binary digits. For our example this is the
number 0.27938402, yielding the sequence
01000111100001011011011, 23 bits. This gives no gain compared to the
Huffman coding example. The reason for this is that the text is
relatively short, and that the probability distribution is close to
optimal for Huffman coding.
. The final code is
some number within this interval. Optimally, we choose the number that
can be coded with less binary digits. For our example this is the
number 0.27938402, yielding the sequence
01000111100001011011011, 23 bits. This gives no gain compared to the
Huffman coding example. The reason for this is that the text is
relatively short, and that the probability distribution is close to
optimal for Huffman coding.
Most variations on these dynamic coding algorithms, stem from one of two methods known as LZ77 and LZ78, which were published by Jacob Ziv and Abraham Lempel in IEEE Transactions on Information Theory [84] [85].
Variations on LZ77 use previously seen text as a dictionary. The main structure in the original LZ77 is a two-part sliding window. The larger part of the window is text that is already coded, while the smaller part, called the look-ahead buffer, contains text that is to be coded. Incoming text is coded by tuples of the form (index, length, successor symbol). Index points to a location within the window on which a match with some of the to-be-encoded text is found. The number of matching symbols is given by length, and successor symbol is the first symbol in the look-ahead buffer that doesn't match.
The algorithm resembles the following:
Figure A.2 shows the contents of the window during the last phase of the coding.
![]()
Figure A.2: The contents of the window at the final step
of LZ77-coding of the text ``abracadabra''.
The first seven symbols are already coded and sent to the output stream, while the last four characters remain to be coded. By inspection, we see that the entire look-ahead buffer match text that is already seen. The final step of the coding thus yields the tuple (1, 4, EOF), where EOF is a special symbol indicating the end of the stream. Since the window is 12 bytes long, we need four bits to encode an index (leaving four possible indexes unused). The look-ahead buffer is four bytes long, so we need two bits to represent the length if we allow zero lengths to be encoded using one of the unused index codes. The input alphabet contains five symbols plus the special EOF symbol, so three bits will suffice for this. Adding it all up, each tuple occupies nine bits.
When coding, the first three symbols each yield one tuple, while the next two pairs each give one tuple since a is found in the window. The four last symbols yield one tuple, giving a total of six tuples, and 54 bits.
Consult [82] for a number of different LZ77 variants, and what to do to increase the performance.
Coders based on LZ78 takes another approach. Instead of using a window of previously seen text, they dynamically build a dictionary of previously seen phrases. New phrases are created by taking a previously stored phrase, and extending it with a single symbol. Initially, there is only one phrase with zero length, the nil-phrase. Like was the case with LZ77, output from an LZ78 coder consists of tuples. The tuples have the form (phrase index, successor symbol). Coding is performed according to the following recipe:
Once again, we code the text ``abracadabra''. Table A.4 illustrates both output from, and dictionary build-up in the coder:

Table A.4: Output from and dictionary generation for
LZ78.
In this setup we need three bits to code the eight dictionary indexes, and three bits for the five symbols and the EOF special symbol. Each tuple thus gives six bits, making a total output of 48 bits.
Index encoding is done differently in the various LZ78 coders. It is possible to let the number of bits output from each tuple vary with the length of the dictionary [82].